Lecture de fichier¶
Il est possible de récupérer les données de différents types de fichiers pour les exploiter sous Python.
Parmi les formats d'exportation les plus courants, on retrouve :
- Excel (
.xlset.xlsx) - CSV (
.csv) - Texte brut (
.txt)
Attention
Même si deux fichiers ont la même extension, ça ne veut pas dire qu'ils utilisent les mêmes conventions d'écritures. Il est donc parfois nécessaire d'adapter les données pour les rendre exploitables par Python.
Info
Pour les formats texte et CSV, on retrouve comme séparateur de colonnes la virgule ,, le point-virgule ;, la tabulation \t, l'espace ou encore les colonnes peuvent être de largeur fixe.
Il faut donc adapter à chaque fois les fonctions de lecture pour correspondre au fichier.
Attention
Python ne reconnait que le point . comme séparateur des décimales.
Donc si vous rencontrez un fichier avec la convention française d'écriture des nombres, il faudra légèrement adapter le code.
Lire un fichier Excel ou LibreOffice¶
Il existe deux formats de fichier Excel :
.xlsqui est l'ancien format d'Excel ;.xlsxqui est le nouveau format d'Excel.
Dans les deux cas, nous allons utiliser le module pandas pour lire les données de ces deux types de fichiers.
pandas utilise comme format de données les DataFrame.
Les différents paramètres de la fonction panda.read_excel(...) sont disponibles ci-dessous :
| Paramètre | Description |
|---|---|
sheet_name | Choix de l'onglet à lire. On peut utiliser un chiffre pour désigner le numéro de l'onglet sheet_name=1 pour le deuxième onglet.Ou donner le nom de l'onglet sheet_name="Feuil1". Il est aussi possible de donner un tableau de plusieurs onglets à lire sheet_name=[0,1,"Feuil6"] qui permet de lire le premier onglet, le deuxième ainsi que celui qui s'appel "Feuil6". |
header | Définit la ligne d'en-tête, par défaut il vaut 0. S'il n'y a pas d'en-tête mettre None |
usecols | Permet de limiter les colonnes à lire dans le fichier. On peut utiliser les lettres comme Excel usecols="A:E" ou usecols="A,C:E".Ou une liste d'entier usecols=(1,2,4). |
skiprows | Nombre de lignes à sauter à partir du début. |
skipfooter | Nombre de lignes à sauter à partir de la fin. |
Lien vers la documentation pandas.read_excel(...).
Info
Vous pouvez aussi lire les fichiers .odf de LibreOffice avec cette fonction.
Cette fonction gère automatique les conventions d'écritures des nombres. Il n'y a pas de modifications supplémentaires à faire.
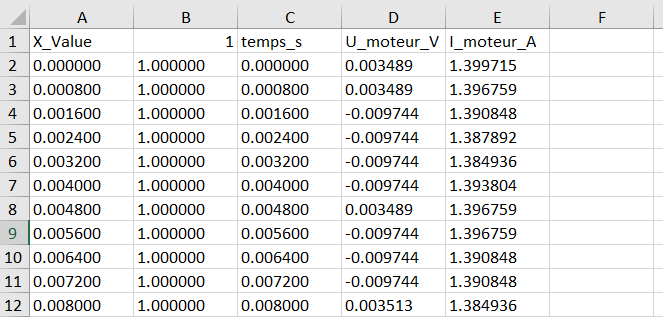
Ancien format .xls¶
Extrait du fichier Data.xls :
import pandas as pd
file = r'Data.xls'
data = pd.read_excel(file, sheet_name=0, usecols=(2,3,4))
print(data.head()) # Affichage des premières lignes de la DataFrame
1 2 3 4 5 6 | |
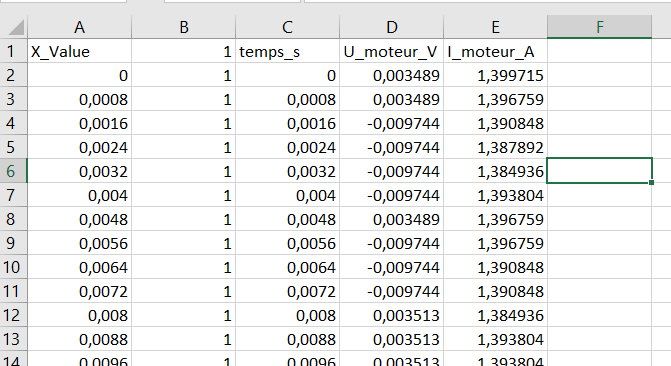
Nouveau format .xlsx¶
Extrait du fichier Data2.xlsx :
import pandas as pd
file = r'Data2.xlsx'
data = pd.read_excel(file, sheet_name=0, usecols="A,C:E")
print(data.head()) # Affichage des premières lignes de la DataFrame
1 2 3 4 5 6 | |
Sélection des données et conversion en tableau numpy¶
Pour faciliter l'utilisation des données, on va les sélectionner une par une et les convertir en tableau numpy.
Pour cela, on affiche les premières lignes pour connaître les données récupérées et on va sélectionner celles qui nous intéressent.
import pandas as pd
file = r'Data.xls'
data = pd.read_excel(file, sheet_name=0, usecols="A,C:E")
print(data.head()) # Affichage des premières lignes de la DataFrame
# On sélectionne la colonne qui porte le nom 'U_moteur_V' et on la convertie en tableau numpy
U_moteur = data['U_moteur_V'].to_numpy()
# De même pour la colonne 'I_moteur_A'
I_moteur = data['I_moteur_A'].to_numpy()
print(U_moteur, "\n", I_moteur) # Affichage des données extraites
1 2 3 4 5 6 7 8 | |
Fichier CSV et texte avec séparateur¶
Pour lire les fichiers csv et texte, on utilise la fonction loadtxt(...) du module numpy.
Les paramètres utilisables sont disponibles ci-dessous :
| Paramètre | Description |
|---|---|
dtype | Permet de définir le type des données. |
delimiter | Permet de choisir le délimiteur de colonnes. |
skiprows | Nombre de lignes à sauter en partant du début. |
usecols | Liste des colonnes à lire. |
max_rows | Nombre maximum de lignes à lire. |
Documentation complète de la fonction loadtxt.
Lecture du fichier avec convention française¶
On utilise le fichier Donnees.csv qui contient les données suivantes :
X_Value;1;temps_s;U_moteur_V;I_moteur_A
0;1;0;0,003489;1,399715
0,0008;1;0,0008;0,003489;1,396759
0,0016;1;0,0016;-0,009744;1,390848
0,0024;1;0,0024;-0,009744;1,387892
0,0032;1;0,0032;-0,009744;1,384936
0,004;1;0,004;-0,009744;1,393804
0,0048;1;0,0048;0,003489;1,396759
0,0056;1;0,0056;-0,009744;1,396759
0,0064;1;0,0064;-0,009744;1,390848
0,0072;1;0,0072;-0,009744;1,390848
0,008;1;0,008;0,003513;1,384936
0,0088;1;0,0088;0,003513;1,393804
0,0096;1;0,0096;0,003513;1,393804
0,0104;1;0,0104;-0,009744;1,393804
0,0112;1;0,0112;-0,009744;1,393804
0,012;1;0,012;0,003489;1,390848
0,0128;1;0,0128;0,003489;1,387892
0,0136;1;0,0136;-0,009744;1,390848
0,0144;1;0,0144;0,003489;1,384936
0,0152;1;0,0152;-0,009744;1,381981
0,016;1;0,016;-0,009744;1,376069
0,0168;1;0,0168;-0,009744;1,373113
0,0176;1;0,0176;-0,009744;1,373113
0,0184;1;0,0184;-0,009744;1,373113
0,0192;1;0,0192;0,003489;1,373113
0,02;1;0,02;-0,009744;1,376069
0,0208;1;0,0208;0,003489;1,373113
0,0216;1;0,0216;0,016747;1,373113
Attention
Ici nous avons un fichier avec la convention d'écriture française.
import numpy as np
# Lecture des en-têtes des données avec comme délimiteur le point-virgule
head = np.loadtxt('Donnees.csv', delimiter=';', max_rows=1, dtype=np.str)
# Lecture des données au format str
data = np.loadtxt('Donnees.csv', delimiter=';', skiprows=1, dtype=np.str)
data = np.char.replace(data, ',', '.')
# Affichage des en-têtes
print(head)
# Sélections des données en fonction de l'en-tête et conversion en flottant
t = np.asarray(data[:, np.where(head == 'temps_s')],
dtype=np.float, order='C').flatten()
U_moteur = np.asarray(
data[:, np.where(head == 'U_moteur_V')], dtype=np.float, order='C').flatten()
I_moteur = np.asarray(
data[:, np.where(head == 'I_moteur_A')], dtype=np.float, order='C').flatten()
# Affichage des données
print(t, '\n', U_moteur, '\n', I_moteur)
1 2 3 4 5 6 7 8 9 10 11 12 | |
Lecture du fichier avec convention anglaise¶
On utilise le fichier Donnees2.csv qui contient les données suivantes :
X_Value;1;temps_s;U_moteur_V;I_moteur_A
0;1;0;0.003489;1.399715
0.0008;1;0.0008;0.003489;1.396759
0.0016;1;0.0016;-0.009744;1.390848
0.0024;1;0.0024;-0.009744;1.387892
0.0032;1;0.0032;-0.009744;1.384936
0.004;1;0.004;-0.009744;1.393804
0.0048;1;0.0048;0.003489;1.396759
0.0056;1;0.0056;-0.009744;1.396759
0.0064;1;0.0064;-0.009744;1.390848
0.0072;1;0.0072;-0.009744;1.390848
0.008;1;0.008;0.003513;1.384936
0.0088;1;0.0088;0.003513;1.393804
0.0096;1;0.0096;0.003513;1.393804
0.0104;1;0.0104;-0.009744;1.393804
0.0112;1;0.0112;-0.009744;1.393804
0.012;1;0.012;0.003489;1.390848
0.0128;1;0.0128;0.003489;1.387892
0.0136;1;0.0136;-0.009744;1.390848
0.0144;1;0.0144;0.003489;1.384936
0.0152;1;0.0152;-0.009744;1.381981
0.016;1;0.016;-0.009744;1.376069
0.0168;1;0.0168;-0.009744;1.373113
0.0176;1;0.0176;-0.009744;1.373113
0.0184;1;0.0184;-0.009744;1.373113
0.0192;1;0.0192;0.003489;1.373113
0.02;1;0.02;-0.009744;1.376069
0.0208;1;0.0208;0.003489;1.373113
0.0216;1;0.0216;0.016747;1.373113
import numpy as np
# Lecture des en-têtes des données avec comme délimiteur le point-virgule
head = np.loadtxt('Donnees2.csv', delimiter=';', max_rows=1, dtype=np.str)
# Lecture des données au format float
data = np.loadtxt('Donnees2.csv', delimiter=';', skiprows=1)
# Affichage des en-têtes
print(head)
# Sélections des données en fonction de l'en-tête et conversion en flottant
t = np.asarray(data[:, np.where(head == 'temps_s')],
dtype=np.float, order='C').flatten()
U_moteur = np.asarray(
data[:, np.where(head == 'U_moteur_V')], dtype=np.float, order='C').flatten()
I_moteur = np.asarray(
data[:, np.where(head == 'I_moteur_A')], dtype=np.float, order='C').flatten()
# Affichage des données
print(t, '\n', U_moteur, '\n', I_moteur)
1 2 3 4 5 6 7 8 9 10 11 12 | |
Lecture fichier texte avec largeur de colonnes fixe¶
Nous utiliserons cette fois la fonction genfromtxt(...) pour extraire les données.
Documentation complète de la fonction genfromtxt.
Soit le fichier MaxPID.txt sous la forme suivante :
Temps Consigne Position Commande Courant Vit. Axe Moteur
ms degrés degrés Volts mA rad/s rad/s
0 89.5 89.6 0.00 2
10 6.6 89.5 -0.16 -64
24 6.6 88.6 -0.43 -118
39 6.6 87.6 -0.66 -140
53 6.6 86.5 -0.82 -164
67 6.6 85.2 -0.98 -172
84 6.6 83.7 -1.13 -184
99 6.6 82.3 -1.24 -184
113 6.6 80.9 -1.42 -193
128 6.6 79.4 -1.43 -190
142 6.6 77.8 -1.53 -200
156 6.6 76.5 -1.61 -195
170 6.6 75.0 -1.65 -205
185 6.6 73.3 -1.71 -198
199 6.6 71.8 -1.76 -206
214 6.6 70.2 -1.82 -200
Note
La largeur n'étant pas forcément connue à l'avance, il est nécessaire de faire plusieurs essais pour avoir les bonnes données.
import numpy as np
# Lecture des en-têtes des données avec un largeur fixe à 10 caractères
head = np.genfromtxt('MaxPID.txt', delimiter=10, max_rows=1, dtype=np.str)
# Lecture des données au format float
data = np.genfromtxt('MaxPID.txt', delimiter=10, skip_header=2)
print(head)
# Sélections des données en fonction de l'en-tête et conversion en flottant
temps = np.asarray(data[:, np.where(head == ' Temps')],
dtype=np.float, order='C').flatten()
position = np.asarray(
data[:, np.where(head == ' Position')], dtype=np.float, order='C').flatten()
print(temps)
print(position)
1 2 3 4 5 6 7 8 9 10 11 12 | |
MaxPID¶
Lors de l'enregistrement des données issues d'une acquisition, le logiciel MaxPid enregistre deux fichiers donc un fichier .txt.
Ce fichier est à colonnes à largeur fixe (exemple MaxPID.txt)
Attention
Par défaut, le logiciel n'enregistre pas l'ensemble de données. Pensez à bien cocher les grandeurs à récupérer.
Par contre, le fichier texte contient l'ensemble des en-têtes même si aucune donnée n'est disponible.
import numpy as np
# Lecture des en-têtes des données avec un largeur fixe à 10 caractères
head = np.genfromtxt('MaxPID.txt', delimiter=10, max_rows=1, dtype=np.str)
unit = np.genfromtxt('MaxPID.txt', delimiter=10, max_rows=1,
dtype=np.str, skip_header=1) # Récupération des unités
# Lecture des données au format float
data = np.genfromtxt('MaxPID.txt', delimiter=10, skip_header=2)
print("En-tête : ", head, '\n')
print("Unité :", unit, '\n') # Affichage des unités
# Pour identifier les colonnes qui n'on pas de données `nan`
print("Première ligne de données :", data[0], '\n')
# Sélections des données en fonction de l'en-tête et conversion en flottant
temps = np.asarray(data[:, np.where(head == ' Temps')],
dtype=np.float, order='C').flatten()
position = np.asarray(
data[:, np.where(head == ' Position')], dtype=np.float, order='C').flatten()
omega = np.asarray(data[:, np.where(head == ' Moteur')],
dtype=np.float, order='C').flatten()
print("Temps :", temps)
print("Position :", position)
print("Vitesse moteur :", omega)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Pilote de bateau¶
Attention
Bien que l'extension du fichier soit en .xls, le format de fichier utilisé est en réalité du CSV avec séparation par tabulation \t.
On utilise le fichier pilote1_ST.xls.
import numpy as np
# Lecture des en-têtes des données avec comme délimiteur le point-virgule
head = np.loadtxt('pilote1_ST.xls', delimiter='\t', max_rows=1, dtype=np.str)
# Lecture des données au format float
data = np.loadtxt('pilote1_ST.xls', delimiter='\t', skiprows=1)
# Affichage des en-têtes
print(head)
# Sélections des données en fonction de l'en-tête et conversion en flottant
t = np.asarray(data[:, np.where(head == 'temps_s')],
dtype=np.float, order='C').flatten()
U_moteur = np.asarray(
data[:, np.where(head == 'U_moteur_V')], dtype=np.float, order='C').flatten()
a_barre = np.asarray(data[:, np.where(head == 'a_barre_°')],
dtype=np.float, order='C').flatten()
print("Angle de la barre :", a_barre)
1 2 3 4 5 6 | |
DAE¶
Le plus simple pour la DAE est de faire un export vers Meca3D.
On se retrouve alors avec un fichier texte à séparateur par espace, mais ayant pour extension .crb
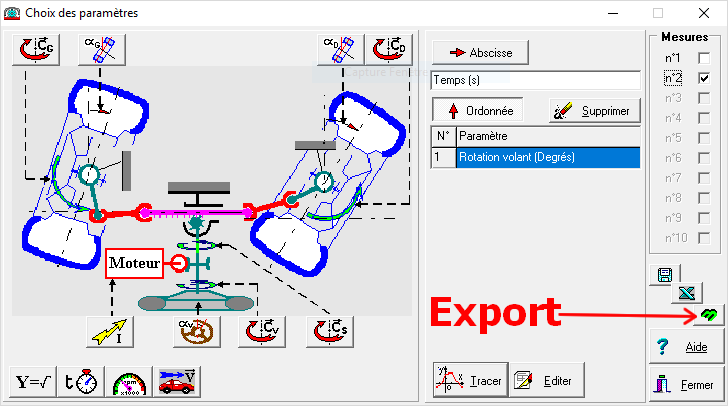
Le fichier exp2.CRB se présente alors sous la forme :
251
XY 0.000000 710.697578
XY 0.040000 710.498040
XY 0.080000 710.498040
XY 0.120000 710.098965
XY 0.160000 700.321613
XY 0.200000 672.386323
XY 0.240000 636.269985
...
import numpy as np
import re
# Lecture du fichier
lines = open('exp2.CRB').readlines()
out = []
for l in lines:
# Suppression des espaces et caractères doublon
l = re.sub('\s+', ' ', l).strip()
# Suppression de la chaîne de caractère en début de ligne
out.append(l.replace("XY ", '') + '\n')
# Extraction des données
data = np.loadtxt(out, delimiter=' ', skiprows=1)
# Affichage de la première ligne pour vérification
print(data[0])
# Sélection des données, les ordonnées correspondent aux colonne 1 à n en fonction des données exportées
abscisse = np.asarray(data[:, 0], dtype=np.float, order='C').flatten()
ordonnee_1 = np.asarray(data[:, 1], dtype=np.float, order='C').flatten()
print(abscisse)
print(ordonnee_1)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
Meca3D¶
Un export texte d'une courbe issue de Meca3D, se présente sous la forme suivante (fichier : Meca3D.txt) :
Position relative de SE_Safran<1> / SE_Bati<1>
a1(rad)
Position a1(rad)
0.000000 -0.698132
1.000000 -0.684169
2.000000 -0.670206
3.000000 -0.656244
4.000000 -0.642281
...
96.000000 0.642281
97.000000 0.656244
98.000000 0.670206
99.000000 0.684169
100.000000 0.698132
Valeur mini ordonnée = -0.698132
Valeur maxi ordonnée = 0.698132
On a donc plusieurs lignes d'en-tête et des lignes de fin en plus. La séparation des colonnes se fait grâce à l'espace.
import numpy as np
# Lecture du fichier
lines = open('Meca3D.txt').readlines()
print(lines[2]) # Affichage de la grandeur exportée et de son unité
# Lecture des données au format float
# On ne lit pas les 3 premières lignes (skiprow=3) ni les trois dernières grâce au slice[:-3]
data = np.loadtxt(lines[:-3], delimiter=' ', skiprows=3)
# Affichage de la première ligne pour vérification
print(data[0])
# Sélection des données
points = np.asarray(data[:, 0], dtype=np.float, order='C').flatten()
valeurs = np.asarray(data[:, 1], dtype=np.float, order='C').flatten()
print(points)
print(valeurs)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |